Features and Targets
In Machine Learning (ML), features are the data points which are used by the model to predict the outcome or target we are interested in. For instance, if we are modelling RG Upgrades, then the target would be "which donors will upgrade their recurring gift in the next 3 months". The features could be any measurable property of the donor, such as the count of their previous donations, their current RG commitment value, their age, and so forth.
Features are also known as factors, predictors, model inputs, X-variables (X-vars), explanatory variables or independent variables. Targets are also known as dependent variables, outcomes, labels or y-variables (y-vars).
Feature Engineering & Domain Knowledge
Typically, raw data sets (such as those existing in fundraising CRMs) are not structured to be suitable for ML. The features and target variables that would be suitable for fundraising questions do not exist in the data in its raw state.
Feature engineering is the name of this process whereby we transform the raw data into features and targets suitable for ML.
For instance, the record of a donor's gifts would be stored in the CRM as a table, with one row for each gift.
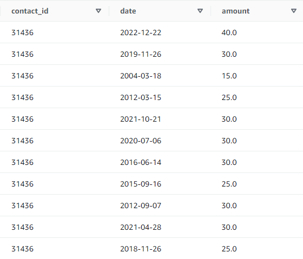
An important property of the data may be the number of gifts a donor has made and to correctly construct it as a feature we would need to express that value as a single variable. The below code snippet demonstrates how we can construct this feature for each donor.
select contact_id,
count(*) as X_number_of_gifts
from raw_revenue r
group by contact_id
In general, feature engineering is an manual and open-ended process that requires considerable domain knowledge of the field, problem and underlying data.
Most models require that the input features be numeric values, however, there are classes of models which can handle categorical, graph or string-based factors.
Therefore, a critical aspect of feature engineering is transforming non-numeric data to relevant numeric variables.
A good example of this a Postal code:
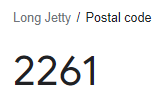
While a Postal code may appear to contain numeric information, it is not a number in the strict sense -- you can't meaningfully add, subtract, multiply or divide a Postal code. The postcode 2262 is not "1 better/bigger/larger" than 2261 in any meaningful sense. If we treat a Postal code as a number for an ML model that expects numeric factors, we can not possibly get a meaningful result!
So, if we wish to use location data in a model, we must engineer numeric features from the Postal code. There are many ways to do this and the items below are hardly exhaustive.
One option could be use an external data set, such as those based on census information and published by national statistical organisations. This dataset can be joined to donor using the Postal code, and contains many potential factors such as average income for the region or proportion of owned vs. rented dwellings.
Another option could be to use an API such as Google maps to derive factors such as, distance to the CBD or number of nearby primary schools.
As mentioned earlier, this is an open-ended process and there is no automatic tool or procedure that can exhaustively derive all the relevant features from a dataset. Domain knowledge is vital here as it will help direct the efforts of the modeller into building features which are most likely relevant to the problem being studied.
A final point here: Feature engineering is probably the most critical aspect of the machine learning process. If you have very good features, you can use an extremely simple model and produce extremely accurate predictions. If your feature set contains many spurious features then you will be much more at risk of overfitting the model during training and your predictions will be unreliable. If you are missing critical features then your model will be very limited as to how accurate it can be.
What features are used by Dataro's models?
The set of features used by Dataro's propensity models is being continuously iterated upon and improved to eke out the best performance from the models.
One of the advantages of ML over RFM and manual segmentation is that it gracefully scales to handle very many features. At the time of writing (March 2023), the complete feature set consists of several hundred features. Generally, the most important of these features are those derived from a donor's donation history, demographic information and communication history.
To get a sense for how the features are constructed, consider a 2D grid where the horizontal axis is historical periods (0-90 days ago, 91-180 days ago, 181-270 days ago, etc,...) and the vertical axis is different categories of donation (Mail Appeal, EDM, RG, P2P, etc,..).
We can allocate every gift a donor has ever made to one of these cells and then we can apply some aggregation function (COUNT, SUM, MAX, AVG, etc,..) to each cell in order to produce a factor.
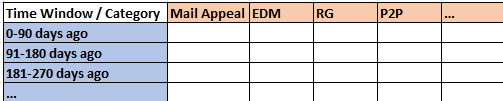
Applying this process to the donation history we can derive many factors such as:
X_mailappeal_0_90_sum_amount
X_p2p_181_270_count
X_rg_gt720_avg_amount
...
This process can also be applied to the communications data. We can use properties of the gifts such as whether the gift was processed successfully and what payment method it was used to create more detailed features. We can use information about the response to a communication to build richer features.
Feature Importance
An ML model will learn some relationship between the features and the target and leverage this information to make future predictions. By inspecting this learned relationship we can understand how the model makes its predictions and which factors are most important for this. The model will learn that some features are more important than others and we can inspect this feature importance.
The way we do this varies by the class of model that is being used.
For instance, a Logistic Regression model learns a parameter (multiplier) for each variable. By examining the magnitude of these parameters, we can directly observe which variables contribute the most to outcome. By observing the sign of the parameter (positive or negative) we can determine whether the factor has a positive or negative correlation to the target.
Dataro employs tree-based models for most use-cases. These models essentially learn a very large IF-ELSE program. These trees can contain many 10s-or-100s-of-1000s of conditional branches and it is not practical for a human to trace each tree and understand how the model is making its decisions. There are, however, a few methods which can estimate the importance of the underlying factors for tree based models, including counting the number of times a feature is used in the trees or calculating the number of samples split by that feature in the training set.
Dataro tracks the feature importance for all its models and these are reflected to the user in the Dataro App in the Model Performance page. As mentioned, we use many features in the models, the exact features may change and the internal naming of the features is not exactly 'user friendly'! For this reason, we roll up the individual features into groups before displaying in the app. For example, here is a sample summary of a DM Appeal Model:

Model Feature FAQ
Can we add to or modify the model features?
Currently users are not able to modify the feature sets used by the models.
Is personally identifiable information (PII) included?
No. No personally identifiable information (PII) is used in Dataro's model training process. The models we build are primarily tree-based classifiers, and they only use numeric input features — for example, something like “sum of appeal gifts in the last 90 days”. The output of these models is simply a score — a number between 0 and 1 — representing how likely a supporter is to take a future action, such as donating to a specific campaign. It is not possible to extract or infer any individual’s identity from either the inputs or the outputs.
How often does Dataro retrain its models?
Dataro retrains models at our discretion. Generally our foundation models are refreshed ever six months, although it may be more or less frequent in some cases.